| ---以往,在医用、工业和军事系统中进行实时视频或图像分析时,设计师通常需要采用昂贵的专用处理器。但随着定点、高性能嵌入式媒体处理器的出现,使低成本的实时图像处理成为可能。为了开发高效的算法,产品设计工程师需要充分利用这些处理器所提供的体系结构特点。本文讨论了数字图像滤波算法能够如何利用嵌入式媒体处理器体系结构的多媒体特性。该Blackfin处理器的特点和指令集可用作一个参照,但是同样的概念通常也适用于其他高性能媒体处理器。
---虽然现在的定点处理器的时钟速率已超过300MHz,但是仅靠增加时钟速率并不能确保实时视频滤波的功能,同样重要的是针对多媒体应用的体系结构特性和专用视频指令。
---大多数视频应用需要处理8bit数据,因为单个像素分量(无论是RGB还是YUV)通常以字节为单位的。因此,8bit视频算术逻辑单元(ALU)和基于字节的地址数据在像素处理中会有很大不同。这一点非常重要,因为数字信号处理器(DSP)通常采用16bit或32bit数据工作。
---另一特点是具有一个灵活的数据寄存器文件。在传统的定点DSP中,字长通常是固定的。然而,数据寄存器的优点是能以1个32bit字(例如R0)或者2个16bit字(例如,R0.L和R0.H分别代表低16位和高16位)来处理数据。这种结构的应用将在下面介绍。
---专用的单周期指令可以非常方便地提供高效的多媒体编码算法。这种应用的一个很好的范例是“绝对差的和”指令能同时将几个像素集之间的差值相加,从而表明在两帧之间的场景变化有多大。 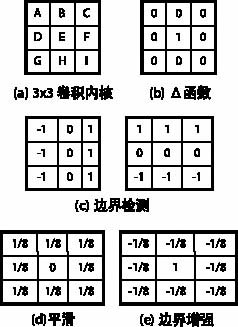 二维图像卷积
---由于一个视频流实际上是一个以一定速率运动的图像序列,所以图像滤波器需要足够快的工作速率才能跟上输入的图像序列。因此,必须优化图像滤波器内核以便占用尽可能最小的处理器周期。这可以通过分析基于二维卷积的一个简单的图像滤波器组来说明。
---卷积是图像处理中的一个基本运算。一个给定像素的二维卷积计算是将其直接的邻域像素的亮度按权值相加。由于一个掩码的邻域集中在一个给定的像素中心,所以该掩码通常具有奇数维数。该掩码的大小通常比图像小,并且经常选用一种3×3的掩码,因为它在每个像素基础上的计算是合理的,但是足够大才可以检测出一幅图像的边界。
---3×3内核的基本结构如图1a所示。例如,位于一幅图像第20行第10列的像素卷积过程的输出应该是:
---Out(20,10)=A*(19,9)+B*(19,10)+C*(19,11)+D*(20,9)+E*(20,10)+F*(20,11)+G*(21,9)+H*(21,10)+I*(21,11)
---重要的是按照一种辅助计算方法来选择系数。例如,比例系数首选是幂指数2(包括小数),因为乘法可以通过简单的移位操作来替换。
---图1b~1e示出了几种有用的3×3内核,每一种内核简述如下。
---图1b示出的Δ函数是最简单的图像处理函数,当前像素不经修改直接输出。
---图1c示出了边界检测掩码的两种常用形式,第一种检测垂直边界,而第二种检测水平边界,高输出值对应较高的边界出现。
---图1d的内核是一个平滑滤波器,它计算当前像素周围8个像素的平均值,并且把结果放在当前像素的位置上。它具有“平滑”或者“低通滤波”图像的作用。
---图1e中的滤波器称为“模糊掩码”操作,它可认为通过从当前像素中减去一个平滑的当前象素(通过取其相邻的8个像素平均值得到)产生一个边界增强的图像。 用嵌入式媒体处理器实现的图像卷积
---进一步讨论二维卷积过程,其高阶算法可按下述步骤。
---(1)将掩码的中心放在输入矩阵上的一个元素上。
---(2)位于该掩码邻域内的每个像素乘以相对应的滤波器掩码元素。
---(3)将每次乘法结果相加得到一个结果。
---(4)将每次相加后的结果放在输出矩阵中掩码中心对应的位置上。
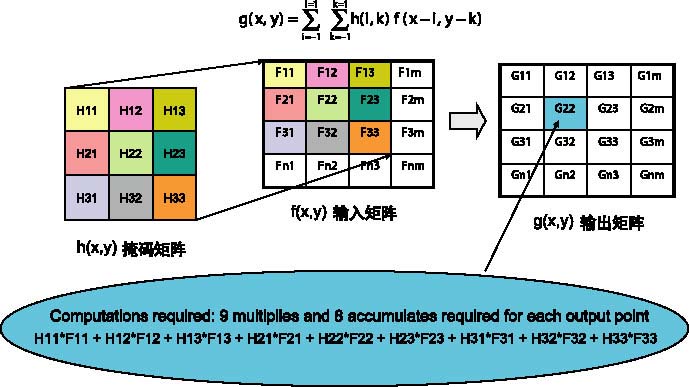
---图2示出了3个矩阵:一个输入矩阵f(x,y),一个3×3掩码矩阵h(x,y)和一个输出矩阵g(x,y)。
---对每个的输出点计算后,该掩码被向右移一个元素。在图像的边界,该算法绕回下一行的第一个元素上。例如,当将掩码集中在以元素F2m为中心时,该掩码矩阵的H23元素乘以输入矩阵的F31元素。结果使输出矩阵的可用部分在图像的每个边界都减少了1个元素。下面考虑将这样一个滤波器放到一个处理器上的要求。
---对于一个30帧/秒帧速率的视频图形阵列(VGA)(640×480像素/帧),其像素速率达到每秒920万像素。现在考虑如果9次乘法和8次加法需要串行实现,运算速度将是(9+8)×9.2 = 156MIPS!如果加法和乘法并行执行,那么运算速度降低为9×9.2=83MIPS。下面的例子将说明如何节省2倍的运算周期。
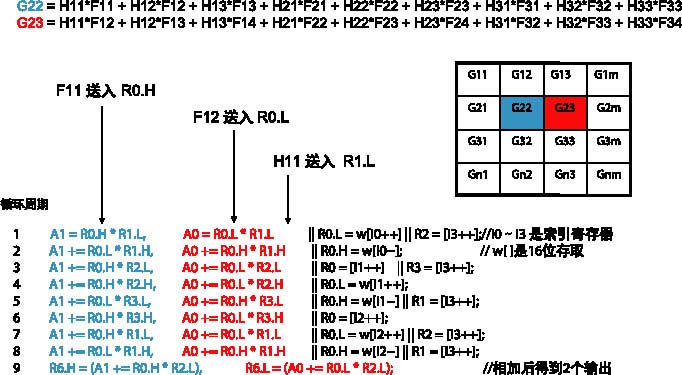
高效二维卷积实例
---对于下面一节将描述的代码,将主要讨论完成所有乘法累加(MAC)运算的“内部”环路。这个示例将证明通过适当地对齐输入数据,MAC单元能够在一个处理器周期内每次处理两个输出点。在同样的周期内,读取多个数据可与MAC运算并行执行。
---这个应用的关键部分是内部循环,如图3所示。内部循环的每条线路都按照单周期指令执行,输入数据以16bit数表示。输入矩阵的开始必须对齐32bit边界。这确保了输入矩阵的两个连续点可以在一个32bit读操作中读出来。在进入此循环之前,该输入矩阵的第一个值保存在R0.H中并且它的第二个值(F12)保存在R0.L中,正如图3示出的第一周期的前2个运算。寄存器R1.L也要在进入内部循环之前装入。它包含掩码矩阵(H11)第一个元素的值。每经过这样一个循环,会产生两个输出点。每两个像素所需的总处理周期为9个,相当于处理一个像素需要4.5个周期。
---正如前面所述,为了获得该输出矩阵的每个元素,需要9次乘法和8次加法运算。但是,由于双MAC运算,2个输出元素可以在每个内部循环结束时获得。因此,F11×H11和F12×H11可以在第一条指令结束时在加法器中获得。内部循环的每条指令都转向下一个掩码值,其结果将在单独的累加法中累加。该内部循环的最终输出装进R6中。
---多个数学运算不仅仅同时出现在每个周期中,而且装入和保存还可并行操作,以便进一步提高效率。还以第一周期为例,下一个输入元素(F13)读入R0.L中,并且在随后的一个指令中用于一个MAC运算。类似地,将下一批掩码值装入R2。这些值用于该内部循环的后续MAC操作。
结论
---在进行图像滤波时,3×3掩码二维卷积是很容易实现的。上面介绍的研究结果示范了如何选择一个适合实时图像处理的处理器,并且了解其结构组成,以便能够提高算法效率并且减少执行周期(这里为原来的1/4)。此外,还能为在同一个平台实现更复杂的图像处理功能提供坚实的基础。 |